Och wann et net mäin immediaten Domaine ass, mee well ech den Ament souwéisou d‘linguistesch Dimensiounen vum Twitter ausloten, hat sich das heutige deutsche TV-Duell zwischen Kanzlerin Angela Merkel und Herausforderer Peer Steinbrück für erste oberflächliche linguistische Analysen geradezu aufgedrängt.
Wie kommentierte die Twittergemeinde den Tatort-Ersatz?
Den Tweet-Sammler habe ich erst um 20:47 angeschaltet und bestimmt einiges verpasst, dennoch wurden bis 23:40 immer noch 152.000 Tweets (70.000 Retweets inklusive) mit dem Hashtag #tvduell verschickt bzw. ließen sich script-gesteuert einsammeln. Dieses Korpus besteht aus 2.1 Mio. Wortformen, die sich auf 68.000 Types verteilen.
Schauen wir uns die ersten 100 Inhaltswörter an. Dabei wurden aus der Liste alle Funktionswörter (Artikel, Präpositionen …), Adjektive und Verben gestrichen und übrig bleiben die für diesen Zweck interessanten Substantive und Namen. Diese 100 Wörter addieren zusammen auf 461.000 Formen und repräsentieren so gut 21 % des gesamten Twitter-Textes. Bei den Nennung rangiert Merkels Name mit ca. 57.000 Nennungen vor demjenigen von Steinbrück mit 44.000 Nennungen. Neben den zu erwartenden Begriffen und Namen wie SPD, fragen, NSA, Vertrauen u.a. sticht ein Wort heraus: Kette (3671), was sich auf die Halskette von Frau Merkel bezieht. Sehr häufig erscheint auch die Form Schlandkette (3546) ‚Deutschlandkette‘ – ein Begriff, der in der Twitter-Gemeinde sehr schnell entstand, aufgegriffen und weiterverbreitet wurde. Synonyme sind Deutschlandkette (768), Belgienkette (47) – weil die Farbreihung nicht ganz stimmte -, Kanzlerinnenkette, Merkel-Kette, Kettengate, Bundeskette, Regenbogenkette, Regierungskette, Schlaaand-Kette, BRD-Halskette, Bundeskanzlerinnenhalskette, D-Landkette, Deutschland-Flagge-Halskette, Haribokette, Hättehättedeutschlandkette und sehr viele mehr. Sie zeigen den spielerischen Umgang mit der Kommentarmöglichkeit, die Twitter über spontane Netzwerkbildung bereitstellt: Instant-Sprachkreativität, die sich in Minutenschnelle (s.u.) im Netzwerk verbreitet (oder verbreiten kann) – über die Relation zu den Themen des TV-Duells und ihre Relevanz überhaupt ließe sich streiten, aber das ist ja auch nicht mein Thema.
Die ersten 100 hochfrequenten Inhaltswörter in Twitter-Reaktionen zum TV-Duell
Rang Wort Anzahl
1 tvduell 121452
2 rt 70431
3 merkel 53238
4 steinbrck 31481
5 raab 14844
6 frau 6816
7 will 6084
8 peersteinbrueck 5272
9 peer 5208
10 angela 5102
11 nsa 4818
12 spd 3735
13 kette 3671
14 frage 3622
15 schlandkette 3546
16 merkels 3358
17 fragen 3173
18 cdu 3160
19 vertrauen 2830
20 tagesschau 2712
21 fdp 2610
22 deutschland 2482
23 steinbrueck 2307
24 redet 2240
25 koalition 2225
26 moderatoren 2159
27 thema 2117
28 herr 2087
29 whlen 2086
30 neuland 2060
31 jahre 1948
32 duell 1940
33 stefan 1814
34 kanzlerin 1783
35 zdf 1634
36 ard 1554
37 reden 1554
38 jauch 1535
39 minuten 1533
40 kanzlerduell 1527
41 land 1524
42 tv-duell 1474
43 niggi 1466
44 gewonnen 1446
45 klppel 1361
46 sehen 1302
47 kloeppel 1281
48 maut 1266
49 twitter 1258
50 rente 1247
51 anne 1238
52 mutti 1225
53 csu 1221
54 kanzler 1213
55 tweets 1187
56 energiewende 1184
57 wahl 1170
58 angie 1163
59 grumpymerkel 1161
60 volker_beck 1156
61 politik 1139
62 abend 1132
63 menschen 1124
64 sigmargabriel 1106
65 seehofer 1090
66 peter 1089
67 ende 1088
68 internet 1073
69 syrien 1067
70 zeit 1057
71 liebe 1046
72 spdde 1038
73 whler 1009
74 wikipedia 995
75 pkw-maut 986
76 jahren 968
77 wort 961
78 geld 960
79 prosieben 954
80 tatort 953
81 belgien 946
82 sieger 943
83 satz 884
84 snowden 882
85 leben 879
86 politiker 864
87 euro 857
88 fazit 852
89 berzeugender 846
90 illner 842
91 tvduellÓ 838
92 muttimachts 825
93 europa 805
94 mindestlohn 796
95 arbeit 790
96 tilojung 788
97 griechenland 781
98 steinbrcks 780
99 piraten 777
100 twitteraccount 777
Corpuslinguistisch prognostiziertes Wahlergebnis
Die Worthäufigkeiten lassen sich nach den verschiedensten linguistischen Kriterien auswerten. Nicht-linguistisch und eher spielerisch ist die Ermittlung der Nennungen der verschiedenen Parteien, was zu einem corpuslinguistisch ermitteltem Wahlergebnis führt.  Demnach kommt die …
Demnach kommt die …
- SPD mit 4.1160 Nennungen auf 33.67%
- CDU mit 2.407 Nennungen auf 27.58%
- FDP mit 2.640 Nennungen auf 21.37 %
- CSU mit 1.264 Nennungen auf 10.23%
- Grünen mit 455 Nennungen auf 3.68%
- Die Linke mit 428 Nennungen auf 3.46%
Entwicklungen im Zeitverlauf
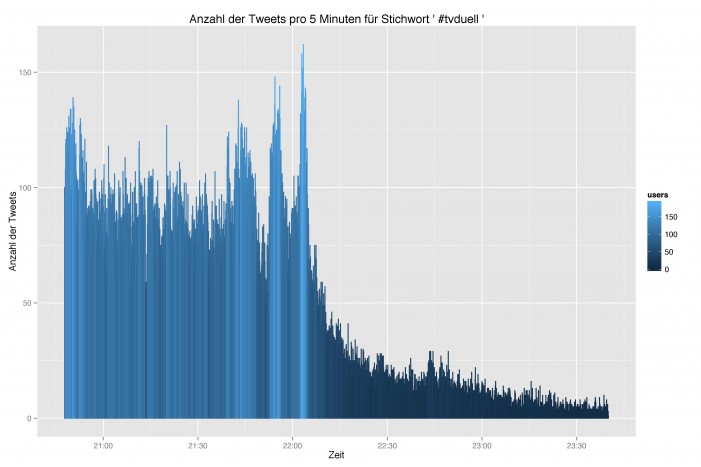
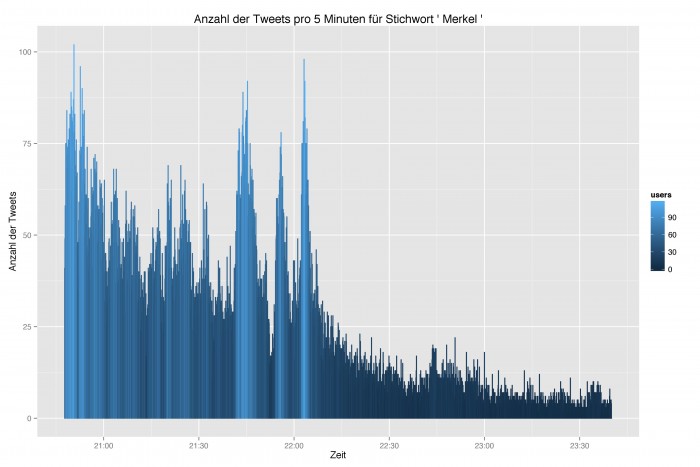
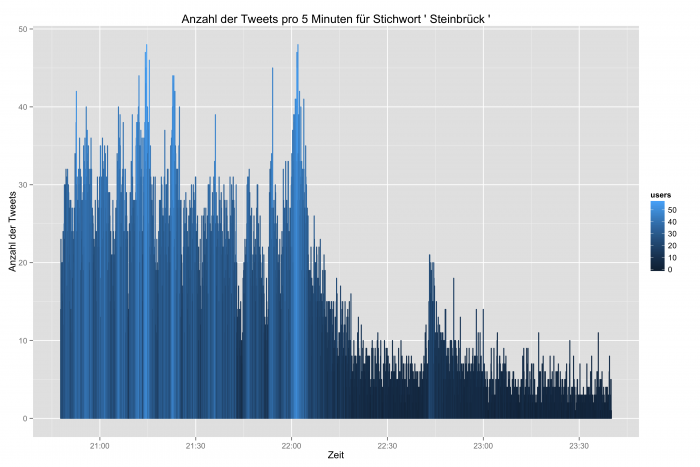
Durch die Auswertung der Zeitstempel lassen sich sprachliche Entwicklungen und Ereignisse – minutengenau – über den Zeitverlauf hinweg beobachten. Die folgenden Abbildungen zeigen die Tweethäufigkeit in 5-Minuten-Abständen. Dabei gibt die Helligkeit zusätzlich die Zahl der Twitterer an.
Zunächst die Nennung des Hashtags #tvduell über den Verlauf von ca. 3 Stunden, das sich im Sendungsverlauf bis 22:00 zwischen 100 bis 150 mal pro 5 Minuten recht häufig findet und danach stark nachlässt:
Es folgen im direkten Vergleich nun die Nennungen der beiden Kontrahenten:
Und schließlich die neu kreierte Schlandkette, die um ca. 20:47 das Licht der Twitter-Welt erblickte.
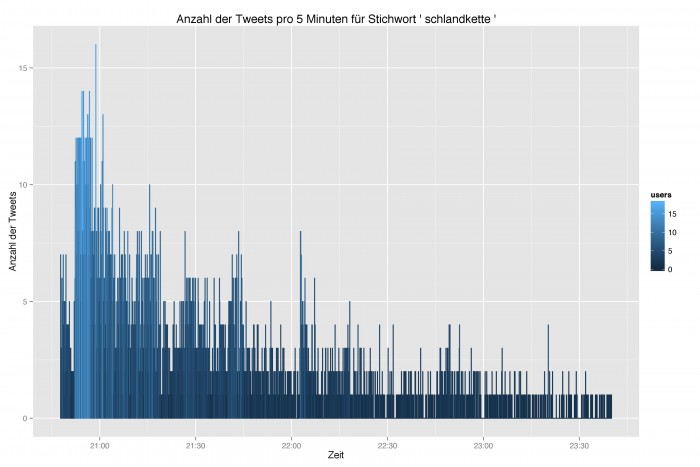
Aus dem relativ schnellen Absinken danach kann auch gefolgert werden, dass es sich um eine lexikalische Neubildung handelt, deren Zukunft ungewiss ist. Aber wer weiß, vielleicht konnte man an diesem Abend die Entstehung eines neuen Wortes in Echtzeit miterleben. Die Verfügbarkeit von Twitter- und anderen Daten und die Auswertungs- und Visualisierungsmöglichkeiten, die sich heute bieten, eröffnen in jedem Fall neue Dimensionen in der Linguistik.
Zum Nachbauen
Tweets sammle ich mit dem modifizierten Python-Script TwitterStream von Gustav Arngården.
R leistet wunderbare Hilfe bei der Auswertung und Visualisierung. Für meine Zwecke angepasst habe ich ein Skript von Michael Bommarito, das sich auf Github findet.
# @author: Bommarito Consulting, LLC; http://michaelbommarito.com/
# @date: May 21, 2012
# @email: michael@bommaritollc.com
# @packages: ggplot2, plyr
# Clear and import.
rm(list=ls())
library(ggplot2)
library(plyr)
# Controlling parameters.
hashtag <- "schlandkette" # Hashtag for label purposes
cutoff <- as.POSIXct("2013-01-09 18:47:49", tz="GMT") # First timestamp we will consider
dt <- 5 # \Delta t, minutes
# Load and pre-process tweets
tweets <- unique(read.csv("tvduellR.csv", sep=",", quote="\"", comment.char="", stringsAsFactors=FALSE, header=FALSE, nrows=300000))
names(tweets) <- c("date", "lang1", "lang2", "text", "location", "user", "description")
# Subsetting für bestimmtes Suchwort/-ausdruck
tweets <- subset(tweets, grepl(hashtag, tweets$text))
tweets$date <- as.POSIXct(strptime(tweets$date, "%a %b %d %H:%M:%S %z %Y", tz = "GMT"))
tweets <- tweets[which(tweets$date > cutoff), ]
# Build date breaks
minDate <- min(tweets$date)
maxDate <- max(tweets$date) + dt
dateBreaks <- seq(minDate, maxDate, by=dt)
# Use hist to count the number of tweets per bin; don't plot.
tweetCount <- hist(tweets$date, breaks=dateBreaks, plot=FALSE)
# Strip out the left endpoint of each bin.
binBreaks <- tweetCount$breaks[1:length(tweetCount$breaks)-1]
# Count number of unique tweeters per bin.
userCount <- sapply(binBreaks, function(d) length(unique(tweets$user[which((tweets$date >= d) & (tweets$date <= d + dt))])))
# Plot data
title = paste("Anzahl der Tweets pro 5 Minuten für Stichwort '",hashtag, "'")
plotData <- data.frame(dates=dateBreaks[1:length(dateBreaks)-1], tweets=as.numeric(tweetCount$count), users=as.numeric(userCount))
ggplot(plotData) +
geom_bar(aes(x=dates, y=tweets, color=users), stat="identity") +
scale_x_datetime("Zeit") +
scale_y_continuous("Anzahl der Tweets") +
opts(title=title)
ggsave(paste(hashtag, ".jpg"), width=12, height=8)